저번 게시글에서는 MSA가 무엇이고 Monolithic Arcitecture나 SOA와는 어떤 부분이 다른지 알아보았다.
이번에는 MSA에서 서비스간 통신을 하기 위한 핵심 기술인 Service Discovery 패턴이 무엇인지 그리고 그것을 어떻게 실제로 적용할 수 있는지 알아보고자 한다.
01. Load Balancer 와 Load Balancing
Service Discovery가 무엇인지 알아보려면 Load Blancer가 어떤 것인지부터 알아야할 필요가 있다.
2010년대 이후 소프트웨어 아키텍처는 Fragile한 Monolithic Arcitecture에서 Anti-Fragile한 Cloud Native Architecture로 점점 변해왔다.
이 Cloud Native Architecture의 큰 특징 중 하나는 오토스케일링을 통해 확장과 축소가 가능한 구조로, 수평적 확장(Scale Out/Scale In)에 유연한 아키텍처다.
이를 통해 시스템은 필요에 따라 인스턴스를 동적으로 생성하거나 삭제하여 부하를 조절할 수 있다.
하지만 이러한 확장성은 "새로 추가된 서버에 트래픽을 어떻게 골고루 분배할 것인가"라는 문제와 연결된다.
이때 필요한 것이 바로 Load Balancer다.
Load Balancer는 등록된 서버들의 연결 정보(IP, Port, Hostname 등)를 가지고 있으며, 다양한 로드 밸런싱 알고리즘을 통해 부하(Load)를 분산(Balancing)하여 각각의 서버가 최적의 퍼포먼스를 유지할 수 있도록 한다.
그렇다면 이 Load Balancer는 각 서버에 대한 연결정보를 가져야 하는데 수시로 CI/CD가 이루어지고 오토 스케일링을 통해 서버의 수가 늘어났다 줄었다 하는 Cloud Native 환경에서 서버에 대한 연결 정보를 사람이 수동으로 등록해야 하는 일은 매우 번거롭고 비효율적인 일이 될 것이다.
02. Service Discovery 패턴이란?
Service Dicovery 패턴은 이런 불편한 점을 해결하기 위한 기술이다.
Chapter 1에서 MSA 도입시 고려사항 몇 가지를 이야기했었는데 그 중 한가지를 인용해 보겠다.
(4) 서비스들의 정보를 어떻게 관리할 것인가?
앞서 MSA에서 외부에서 오는 요청은 API Gateway를 통해 전달되고, 서비스간 통신도 이루어진다고 했다.
이때, API Gateway는 어떻게 애플리케이션의 정보를 알아서 전달하고, 각 서비스들도 어떻게 다른 애플리케이션들의 정보를 알아서 통신하는 걸까?
API Gateway에 모든 애플리케이션 정보를 수동으로 등록하고 각 서비스에서도 다른 서비스들의 정보를 수동으로 등록하면 간단(?)하게 해결된다.
그러나 이것은 너무 비효율적인 방법이며 애플리케이션을 운영하다보면 생길 수 있는 서비스의 확장이나 축소에도 너무 많은 리소스가 들어가게 된다.
그렇기 때문에 MSA에서는 이러한 과정들을 각 서비스들의 정보를 등록/관리하는 Service Discovery 패턴을 통해 처리한다.
요약해보자면, MSA를 도입하게 됐을 때
각각의 마이크로 서비스가 확장/축소될 때마다 해당 서비스의 정보(IP,Port)를 수동으로 업데이트 해야한다는 점이 불편하고 이것을 해결하기 위한 방법이 Service Discovery 패턴이라는 것이다.
Service Discovery는 'Service Registry'로서의 역할을 하는데, 쉽게 말해 서비스의 위치(IP, Port 등)를 저장 및 관리하는 서비스들의 주소록 역할을 한다는 뜻이다.
Service Discovery 패턴을 구현함으로써 서비스를 호출하는 쪽(Load Balancer, API Gateway)에서는 서비스의 위치를 몰라도 Service Discovery를 구현한 구현체에게 서비스의 위치를 물어봄으로써 요청을 전달할 수 있다.
외부에서 API Gateway를 통한 요청과 서비스간 통신 모두 Sevice Discovery를 거쳐서 요청을 전달하게 된다.
03. Server-Side Discovery / Client-Side Discovery
Service Discovery 패턴에는 두 가지 종류가 존재한다
- Server-Side Dicovery
- Client-Side Discovery
두 가지를 나누는 기준은 'MSA의 다른 서비스를 호출할 때 무엇을 통해서 호출하는가'이다.
Server-Side Discovery는 Load Balancer를 통해 다른 서비스를 호출하고
Client-Side Discovery는 Service Registry를 통해 서비스를 호출한다.
1) Server-Side Discovery

Server-Side Discovery는 앞서 말한 것처럼 다른 서비스를 호출할 때 Service Registry를 거치지 않고 앞단에 물리적인 Load Balancer를 배치해 이 Load Balancer가 내부의 Service Registry에게 결과를 반환받는 형태의 Service Discovery 패턴이다.
장점
- 각 서비스들이 다른 서비스를 호출할 때 Load Balancer에 요청을 보내도록 설계되므로 Service Registry의 구체적인 구현형태는 모른채로 Load Balancer만 호출하면 된다. => 추상화된 Load Balancer만 호출하면 되고. Service Registry는 캡슐화되어 있다.
- 추상화된 Load Balancer에 요청만 보내면 되므로 다른 서비스를 검색하는 로직을 구현할 필요가 없다.
단점
- 배포 환경에서 앞단에 로드밸런서를 배치하는 것이 필수적이다.
- 요청 시 Load Balancer를 한 단계 거쳐야하므로 네트워크 hop이 증가하여 처리가 상대적으로 지연된다.
2) Client-Side Discovery

Client-Side Discovery는 Server-Side Discovery와는 다르게 각 서비스들이 Service Registry에게 직접적으로 질의하고 결과를 반환받는다.
Client-Side Discovery에서는 Server Registry를 구현하는 라이브러리들을 사용하는데 대표적인 라이브러리가 조금 있다 사용해 볼 Spring Cloud Netflix Eureka다.
장점
- 인프라단에 Load Balancer를 배치하는 작업을 하지 않고, 애플리케이션 코드단에서 Service Discovery 패턴을 구현하기 때문에 상대적으로 간단하다.
- 각 서비스들이 호출하려는 서비스를 알기 때문에 서비스별로 특성에 맞게 로드밸런싱을 구현할 수 있다.
단점
- 각 서비스 별로 다른 서비스를 검색하는 로직을 언어 및 프레임워크별로 구현해야 한다.
- 따라서 각 서비스가 Service Registry 의존적이다.
- Polyglot(다언어 환경)한 시스템이라면 언어 및 프레임워크 별로 여러 번 구현해야하기 때문에 비효율적이다.
04. Eureka란?
Service-Side Discovery와 Client-side Discovery까지 알아보았으니 이제 실제로 Service Discovery 패턴을 구현해볼 차례다.
이번 프로젝트에는 Service-Side Discovery가 아닌 Client-Side Discovery 그 중에서도 Eureka 라이브러리를 활용하여 프로젝트를 진행할 계획이다.
이유는 다음과 같다.
- 인프라 작업이 아닌 애플리케이션 코드단 작업이기 때문에 상대적으로 접근이 쉽고 간단하다.
- Eureka를 사용한 레퍼런스가 압도적으로 많다.
- 현재 프로젝트는 Java & Spring만 사용하는 단일언어 환경이다.
앞서 Service Discovery는 Service Registry의 역할을 한다고 했다.
각각의 서비스들의 연결 정보를 저장하고 있는 데이터베이스 역할을 한다는 것으로 높은 가용성이 보장되어야하고 항상 최신 정보를 유지해야한다.
Eureka는 이런 Service Registry로서의 역할을 지원하기 위한 라이브러리로 Eureka Server 와 Eureka Client로 나뉜다.
- Eureka Server : Eureka Service가 자기 자신을 등록(Service Registration)하는 서버이자 Eureka Client가 가용한 서비스 목록(Service Registry)을 요청하는 서버
- Eureka Client : Eureka Server에 자신의 위치 정보를 등록하고 다른 서비스의 위치 정보를 요청하는 서비스
Eureka는 이 Eureka Server와 Eureka Client를 활용하여 등록된 서비스 모듈이 유기적으로 스스로 상호작용하는 흐름으로 운용된다.
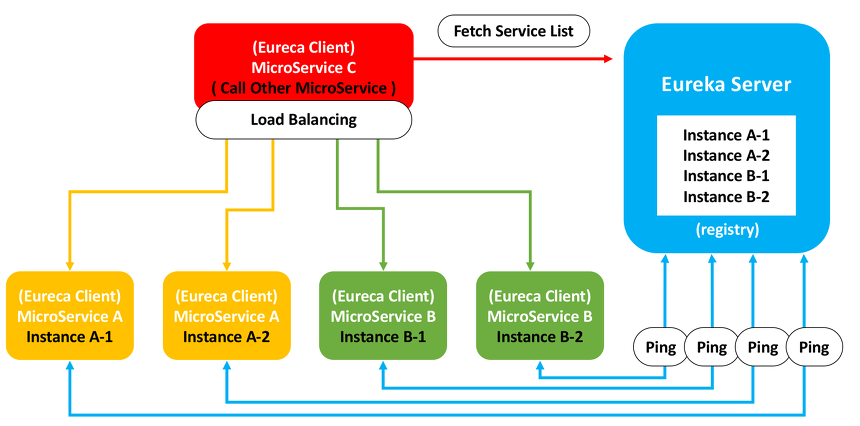
- Eureka Client 서비스가 시작 될 때 Eureka Server에 자신의 정보를 등록한다.
- Eureka Client는 Eureka Server로 부터 다른 Client의 연결정보가 등록되어 있는 Registry를 받고 자신의 Local에 저장하게 된다.
- 30초 마다 Eureka Server로 부터 변경 사항을 갱신받는다.
- 30초 마다 ping을 통하여 자신이 동작하고 있다는 신호를 보낸다. 신호를 보내지 못하면 Eureka Server가 보내지 못한 Client를 Registry에서 제외시킨다.
05. Eureka 활용 예제
1) Eureka Server
build.gradle
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'
}application.yml
server:
port: 8761
spring:
application:
name: discovery-service
eureka:
client:
register-with-eureka: false # 이 인스턴스가 다른 사용자가 검색 할 수 있도록 해당 정보를 eureka 서버에 등록해야하는지 여부를 나타냄
fetch-registry: false # 이 클라이언트가 유레카 서버에서 유레카 레지스트리 정보를 가져와야하는지 여부를 나타냄DiscoveryserviceApplication.class
@SpringBootApplication
@EnableEurekaServer
public class DiscoveryserviceApplication {
public static void main(String[] args) {
SpringApplication.run(DiscoveryserviceApplication.class, args);
}
}메인 클래스엔 @EnableEurekaServer 어노테이션을 부착해 Eureka Server로 등록해준다.
2) Eureka Client
build.gradle
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
}application.yml
server:
port: 0 # 0으로 설정시 랜덤 포트
spring:
application:
name: my-first-service
eureka:
client:
fetch-registry: true
register-with-eureka: true # eurkea서버로부터 인스턴스들의 정보를 주기적으로 가져올지 설정하는 속성, true시 받겠다는 뜻
service-url:
defaultZone: http://localhost:8761/eureka
instance:
instance-id: ${spring.application.name}:${spring.application.instance_id:${random.value}}eureka.instance.instance-id의 값을 통해 인스턴스 고유 ID 표기 방식을 변경할 수 있다.
(기본값은 호스트 + 어플리케이션 이름 + 포트 번호)
eureka.client.serviceUrl.defaultZone은 Eureka Server의 주소 + /eureka/를 입력하면 된다.
'Develop > Java & Spring' 카테고리의 다른 글
| [MSA] MSA 전환 프로젝트 - 4. Spring Cloud Config (0) | 2025.03.26 |
|---|---|
| [MSA] MSA 전환 프로젝트 - 3. API Gateway & Spring Cloud Gateway (0) | 2025.03.26 |
| [MSA] MSA 전환 프로젝트 - 1. MSA란? (0) | 2025.03.26 |
| [Spring Boot] 게시판 프로젝트 v2.0 - JWT를 이용한 회원가입 및 로그인 구현 #6 Config, Filter, DTO, Contoller (0) | 2025.03.26 |
| [Spring Boot] 게시판 프로젝트 v2.0 - JWT를 이용한 회원가입 및 로그인 구현 #5 Domain, Repository, Service (0) | 2025.03.26 |